
Организация поиска на сайте: выбираем между поиском Битрикса, Sphinx и Elasticsearch
- Влияние поисковой строки на конверсию
- Как работает встроенный поиск Битрикса
- Как забустить поиск Битрикса
- Переводим поиск на Elasticsearch
Обычный пользователь должен чувствовать, что поиск на сайте — это просто. Он привык к интеллектуальным возможностям поиска в Google и Яндексе, и от любой другой поисковой строки по умолчанию ожидает того же. Набираешь, например, «телискп» или «пороцитомол» и получаешь список оптических приборов и фармпрепаратов с указанием разделов каталога в котором они находятся.
Как поисковая система сайта понимает что пользователь имел в виду на самом деле? Магия или наука? Попробуем разобраться чем грозит бизнесу недостаточное внимание к внутреннему поиску, как он помогает сократить путь пользователя и улучшить конверсию.
Влияние поисковой строки на конверсию
Поисковая строка на сайте — это часть вашей воронки продаж.
Нулевая выдача на запрос = потеря клиента. Если пользователь не нашел то, что искал, — вы ему это не продадите.

Клиенты, которые пользуются поиском по сайту, могут приносить коммерческому интернет-ресурсу до 50% дохода.
Сравним две аудитории интернет-магазина: одна из них пользуется внутренним поиском, другая — нет. Доля аудитории, которая пользуется внутренним поиском, составляет 12%. Но именно она приносит интернет-магазину 43% дохода.
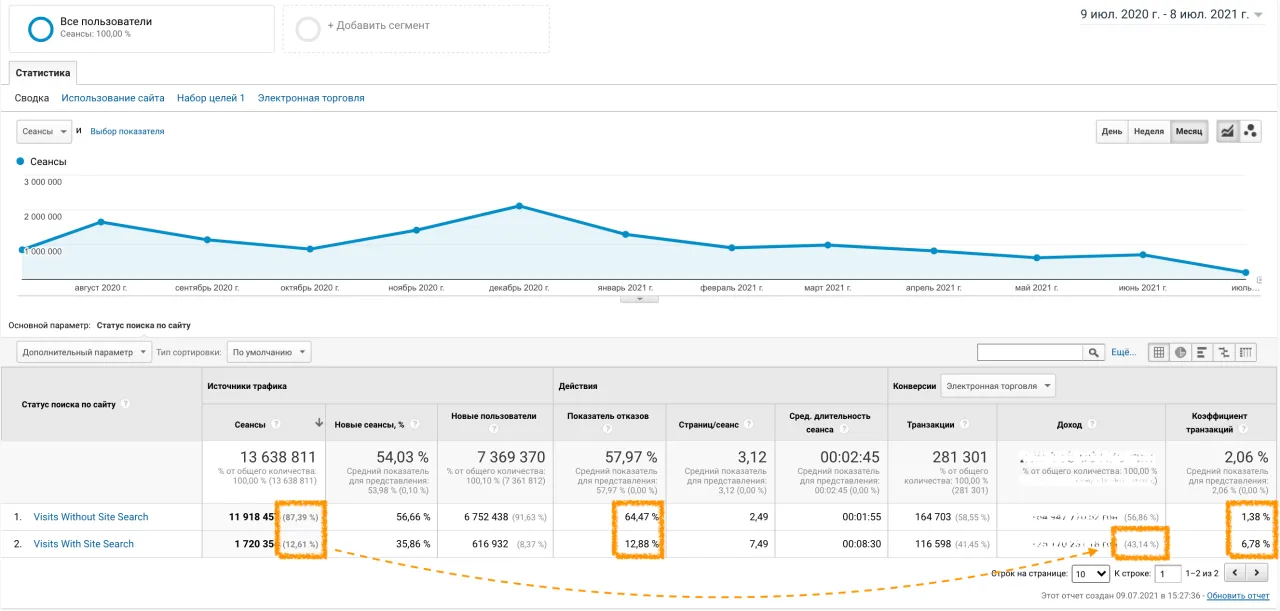
Базовый минимум для современного «умного» поиска.

Справится ли Битрикс с такой задачей? По умолчанию — нет.
Как работает встроенный поиск Битрикса
Стандартный поисковый модуль в «1С-Битрикс: Управление сайтом» хорошо решает свои задачи, когда нужно просто что-то найти без сложного контекста и условий. Используя точную семантику запроса он ищет по всему тексту, заголовкам, полям и тегам в различных разделах сайта (каталог, новости, база знаний, блог, о компании и пр). Такой полнотекстовый поиск вполне подходит, если на сайте представлен небольшой ассортимент, не требуется фильтрация, не нужно включать в выдачу промо-позиции и совершать какие-либо сложные конверсионные действия.
Однако, если нужно администрировать товарный агрегатор или интернет-магазин с большим каталогом, то придется докрутить поиск. Например, ограничить его только инфоблоками с товарами и SKU, чтобы, помимо них, Битрикс не выдал сборную солянку из ленты новостей, статей и «полезной» информации со служебных страниц. В таком случае клиенту удобнее и проще вернуться к выдаче Яндекса, чем продолжать тратить время на вашем сайте.

Почему так получается?
Сначала штатный поиск Битрикса делит предложение на части и отбрасывает предлоги, союзы, частицы. Дальше приводит все слова в начальную форму и сохраняет их в таблицах базы данных. В одной таблице сохраняются все начальные формы слов, в другой — все тексты, третья связывает конкретное слово с конкретными текстами. N-граммы не строятся, поэтому Битрикс не умеет исправлять ошибки и искать по части слова или артикула, но умеет различать окончания слов. Для этого у него есть специальная настройка — учитывать/ не учитывать морфологию. Если она учитывается, поиск идет по словоформам, если нет — по точному вхождению.
Так как в ответ на запрос могут включаться все словоформы, то совпадений с текстами из базы будет много и мы получим много похожих результатов в выдаче. А это негатив для тех, кто хочет быстрых и точных ответов.
Есть и другие нюансы, способные плохо влиять на конверсию сайта с поиском по умолчанию. Так, на запрос с орфографической ошибкой или неверной цифрой в коде товара ответ будет нулевым, как и конверсия из поиска в переход к товарной карточке.
Чтобы нивелировать недостатки полнотекстового поиска его дополняют фасетной фильтрацией, но это ещё несколько лишних шагов на пути к покупке. А между тем посетители, которые ищут непосредственно на сайте, более конверсионные, чем остальная аудитория. Они уже знают, что хотят купить.
Как забустить поиск Битрикса
C версии 14.0.0. в продуктах «1С-Битрикс» доступна поддержка системы полнотекстового поиска Sphinx. Она позволяет искать быстрее и лучше, снижает нагрузку на сервер, а также полностью интегрирована с компонентами модуля «Поиск». К сожалению, актуальная версия 3.х.х ядром Битрикса еще поддерживается.
Из плюсов Sphinx:
-
высокая масштабируемость, скорость индексации и поиска;
-
наличие трех встроенных (ru, en, cs) и 12 подключаемых морфологических плагинов лемматизации (приведение слова к словарной форме) и стемминга (нахождение основы слова для заданного исходного слова);
-
full-text, фасетный, geo поиск и индексация;
-
поддержка стоп-слов, на случай, если нужно убрать некоторые слова из поисковой выдачи;
-
распределенный поиск на нескольких нодах (запущенных экземплярах Sphinx) в кластере;
-
готовые интеграции для различных платформ и фреймворков;
-
умеренное использование серверной памяти.
Минусы:
-
ограниченный API и отсутствие дефолтного нечеткого (fuzzy) поиска;
-
необходимость ручной настройки структуры индексов, что усложняет масштабирование;
-
снижение производительности при увеличении объемов данных;
-
нет возможности визуализации;
-
маленькое сообщество.
Быстрая индексация делает Sphinx идеальным для проектов с низкими требованиями к поисковым функциям. Но что делать, если проект вырос, вы хотите масштабироваться или вам требуется гибкое управление поисковой выдачей?
Переводим поиск на Elasticsearch
Обычно про него заходит речь когда текущая поисковая система сайта чем-то не устраивает. В связке с другими продуктами разработчика (т.н. Elastic Stack, ELK) этот инструмент предоставляет ещё больше возможностей в управлении поиском и представлении данных.
Elasticsearch (ES) — это нереляционное хранилище документов с собственным REST API, работающее с данными в формате JSON.
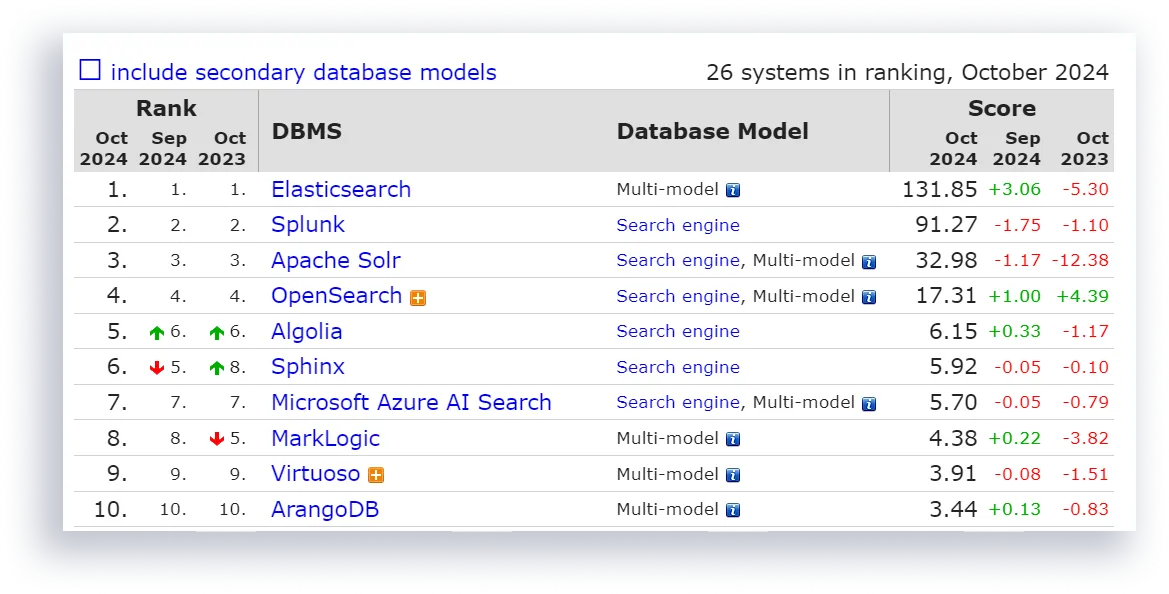
Elasticsearch — постоянный лидер рейтинга DB-Engines.
Отличий Elasticsearch от Sphinx много. Вот самые важные.
-
Масштабируемость. Как и Sphinx, ES предлагает высокую степень горизонтальной масштабируемости, позволяя распределять и реплицировать данные на множество узлов и шардов. Но Sphinx требует ручного управления структурой индексов, а Elasticsearch позволяет «на лету» добавлять новые узлы к уже имеющейся системе и автоматически распределять на них нагрузку.
-
Возможности API. ES поддерживает широкий спектр сложных запросов и мощные функции агрегации и фильтрации для анализа данных, может отдавать их напрямую из поискового движка. У Sphinx API победнее, что заставляет постоянно дергать её БД запросами.
-
Структура данных. ES лучше работает с мультиязычными системами и неструктурированными данными, а Sphinx быстрее индексирует структурированные базы: форумы, интернет-магазины, чаты, каталоги. Для мультиязычных систем, в случае Sphinx, придется построить отдельные индексы по разным языкам, отдельно настраивать морфологию, стемминг, параметры нечеткого поиска. Elasticsearch, напротив, проанализирует и зальет данные в отдельный индекс, настроит параметры под нужный язык. Данные будут изолированы, а поиск станет работать быстрее. Эффективная работа с неструктурированными данными позволяет успешно применять ES в рекомендательных системах.
-
Отказоустойчивость. Sphinx не поддерживает автоматическое управление репликацией и шардированием, что делает его менее устойчивым к сбоям по сравнению с Elasticsearch, повышает нагрузку на администраторов системы.
-
Хранение и анализ логов, визуализация данных. Сегодня это почти must-have любого интернет-проекта, но представлять данные в удобном для анализа виде умеет только экосистема ELK. Она может обрабатывать гигабайты данных от балансировщиков, гипервизоров и коммутаторов и представлять их в виде удобных дашбордов. Помимо этого Elasticsearch использует возможности машинного обучения (ML) для улучшения анализа данных и поиска.
Elasticsearch для поиска
Для организации и хранения данных Elasticsearch использует индексы. Индекс — это логическое хранилище, в котором организованы документы одного типа. Каждый индекс состоит из одного или нескольких шардов (частей), что позволяет распределять данные по различным узлам кластера для обеспечения отказоустойчивости и масштабируемости.
Чтобы данные попали в индексы ES их нельзя просто взять и затянуть из базы данных сайта «как есть». Эти «сырые» данные нужно проиндексировать. Для создания индекса используют собственный API системы, который нужно откуда-то вызывать. Это могут делать обработчики событий в Битриксе или агент, который будет периодически обновлять данные, или сервер очередей. Очень удобно работать с Kibana из стека ELK.
Ниже представлен пример индекса с ручным маппингом полей. Индекс можно создать с помощью REST API или готовой библиотеки для работы с ним. Маппинг может быть и динамический, но обычно этой штуке нельзя полностью доверять. Лучший результат получается при комбинации динамического и явного маппинга, можно создавать свои хитрые правила сопоставления полей.

Загружаем в индекс товары.
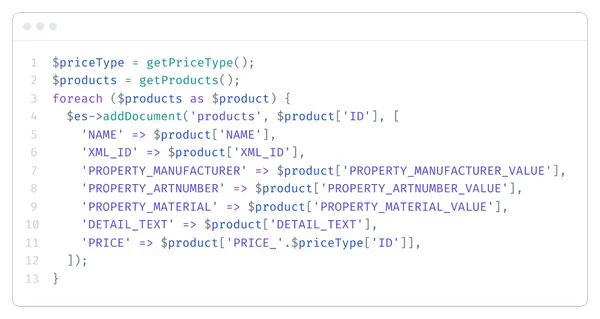
Получаем товары в индексе.

Пробуем найти «Туфли».
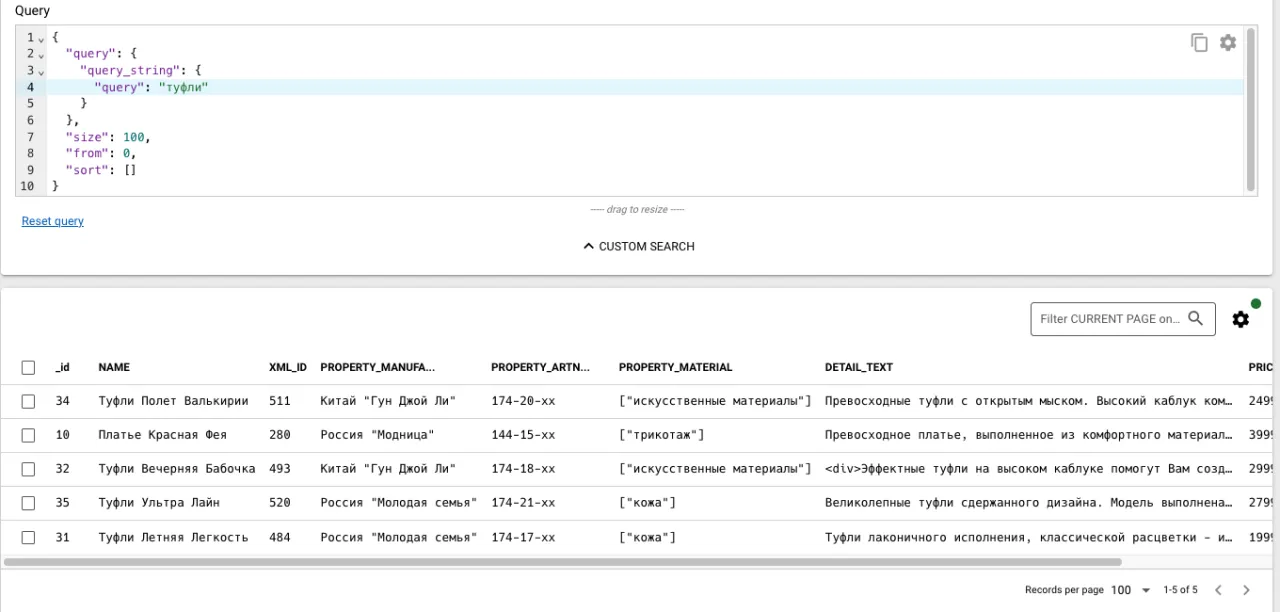
В выдаче получаем «Платье Красная Фея», т.к. «туфли» могут быть не только в названии искомого товара, но и в описании других товаров.
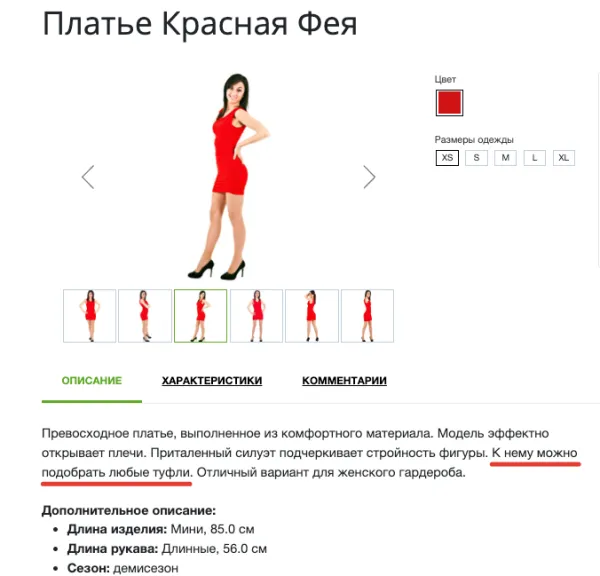
В этом случае можно скорректировать запрос и искать только в названии, но…
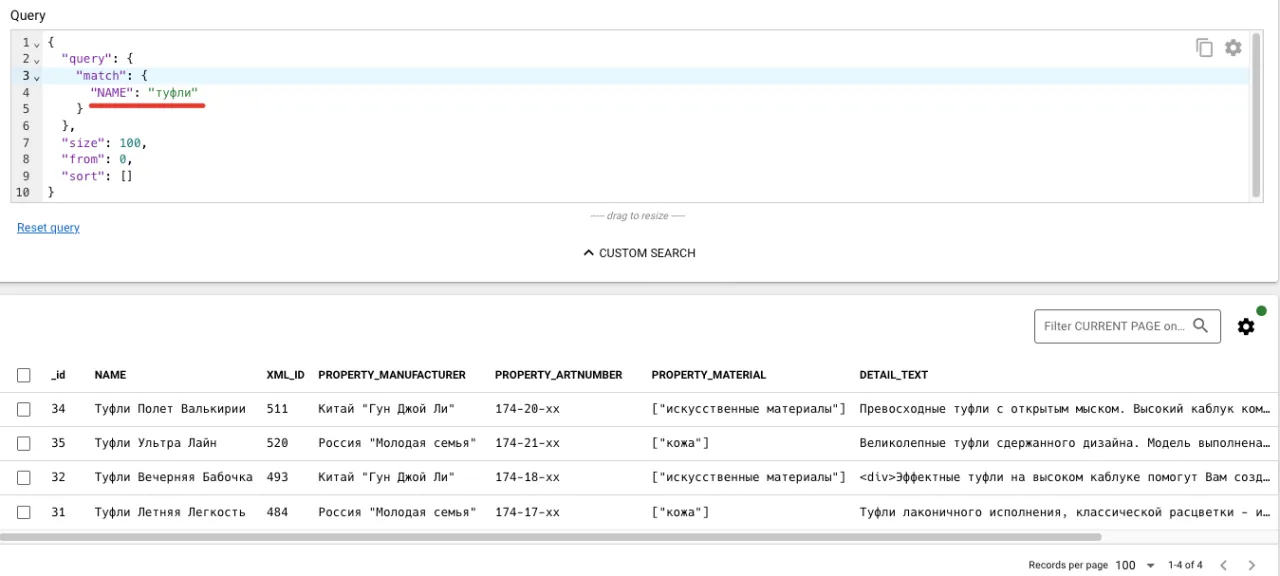
… мы еще не видели магазина, где нужен был бы поиск только по названию товара, а не по описанию, значению свойств и тд.
Можно пойти по другому пути и расставить приоритеты (веса) полей.
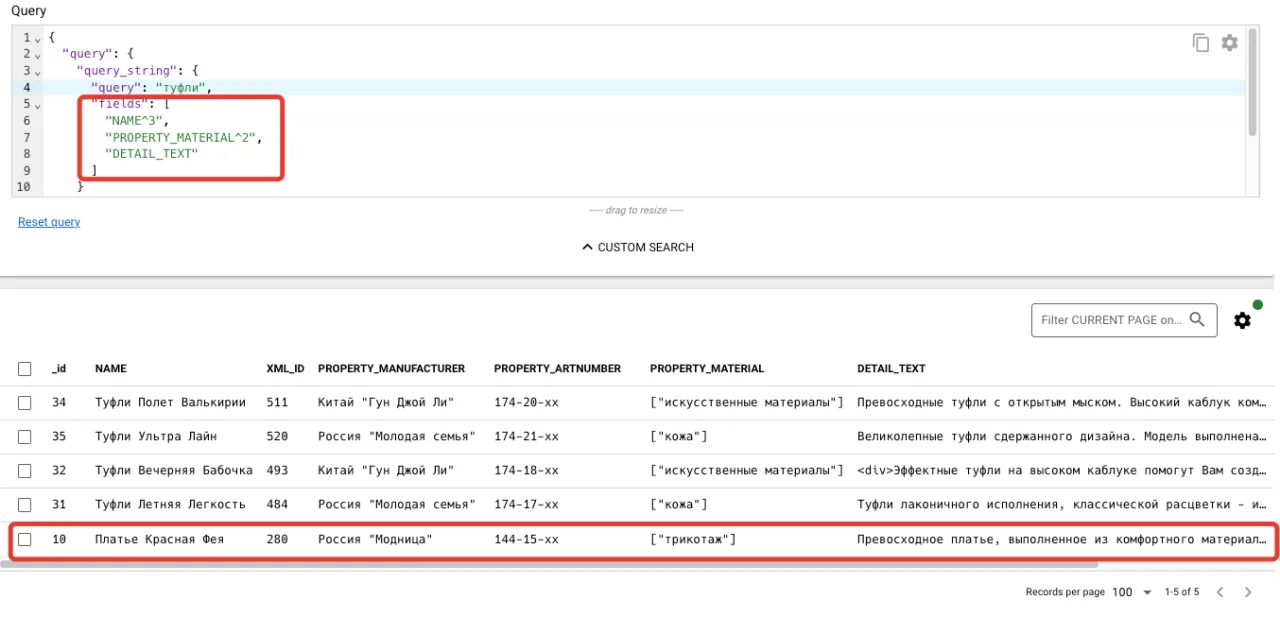
Это позволяет гибче управлять ранжированием в зависимости от того, в каком поле нашлись совпадения.
Результаты выдачи также зависят от используемого анализатора, который преобразует оригинальный текст в структурированный формат, оптимизированный под эффективное хранение и быстрый поиск. В ES несколько встроенных анализаторов, результаты их работы отличаются.

Не всегда удается получить от стандартных анализаторов то, что нужно. В таком случае можно сделать свой, доработав один из его элементов — токенайзер. Есть несколько доступных токенайзеров, например, N-gram tokenizer или Edge-ngram tokenizer. Последний обычно используется для анализа запросов по мере ввода.
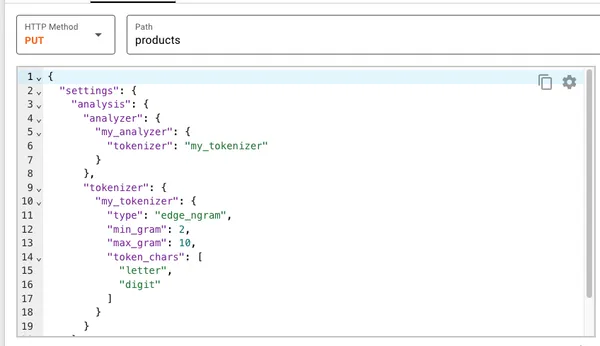
Пробуем искать еще раз.
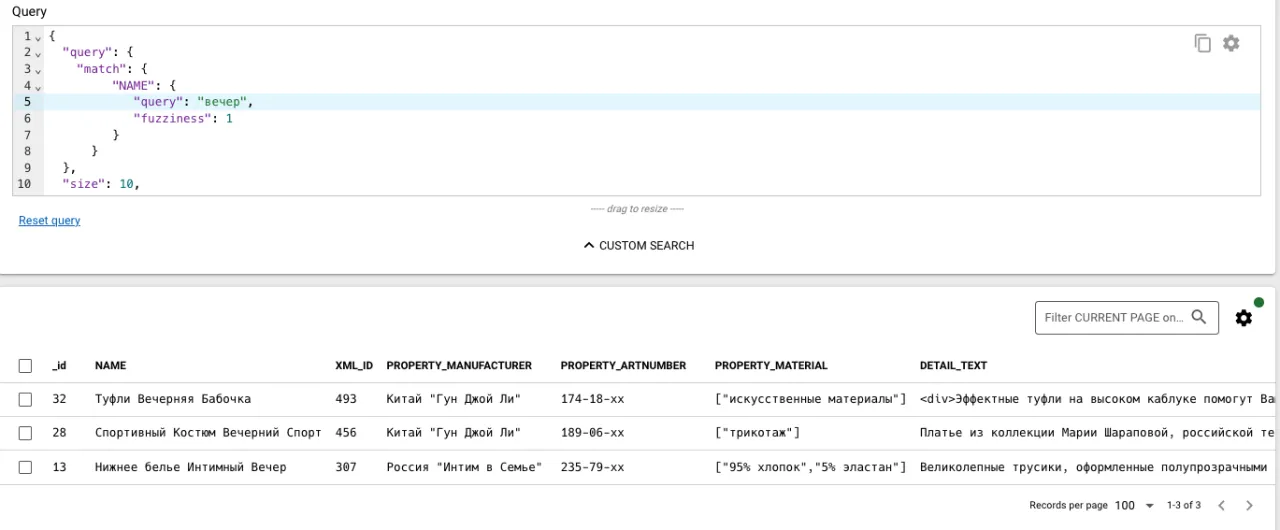
Elasticsearch нашел «вечер» в различных словоформах из разных категорий каталога. То что нужно!
Как хранить каталог в Elasticsearch
Все зависит от структуры и данных, по которым нужно искать.
-
Один индекс с товарами — если нет SKU (или есть, но в выборке для каталога не участвуют).
-
Один индекс с SKU и информацией о товарах.
-
Индекс с товарами + индекс с SKU и Parent-Child Relationship. Вложенные сущности делать можно, но на большом объеме данных и при большом количестве запросов (нагруженный интернет-магазин) это будет работать очень медленно.
-
Всё храним в одном индексе — Nested objects. Здесь есть ограничение в 1000 уникальных свойств на индекс, но за него можно будет выйти, если у нас действительно много свойств у товаров. И это, конечно, скажется на производительности.




Как создать «умный» фильтр
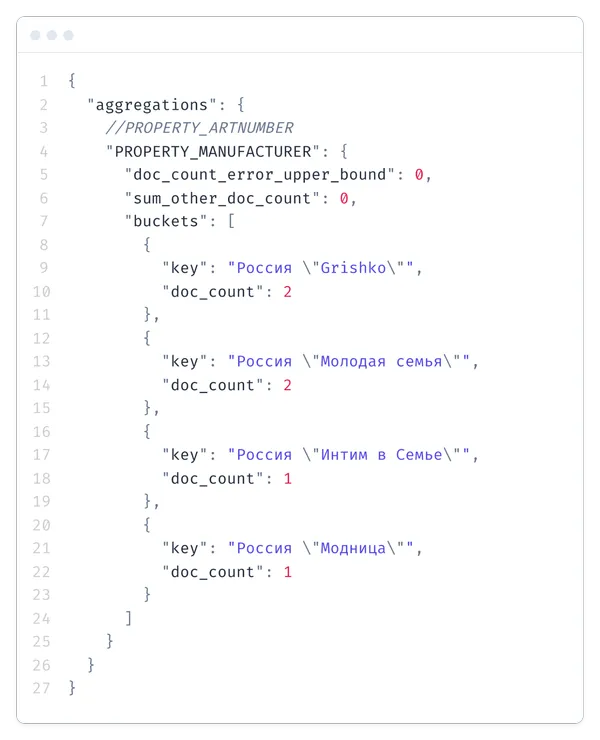
Такой фильтр реализуется за счет механизма агрегаций и уже в нем можно получить нужные данные, без отдельного запроса к БД. Правда из-за этого запрос в ES становится примерно на 10% медленнее.
В mapping для текстовых полей добавляем raw с типом <keyword>.

В поисковый запрос добавляем узел aggs.

В ответе на запрос появится новый узел, где будет вся нужная нам информация.
Для свойства «Артикул».

Для свойства «Производитель»
Elasticsearch для управления логами
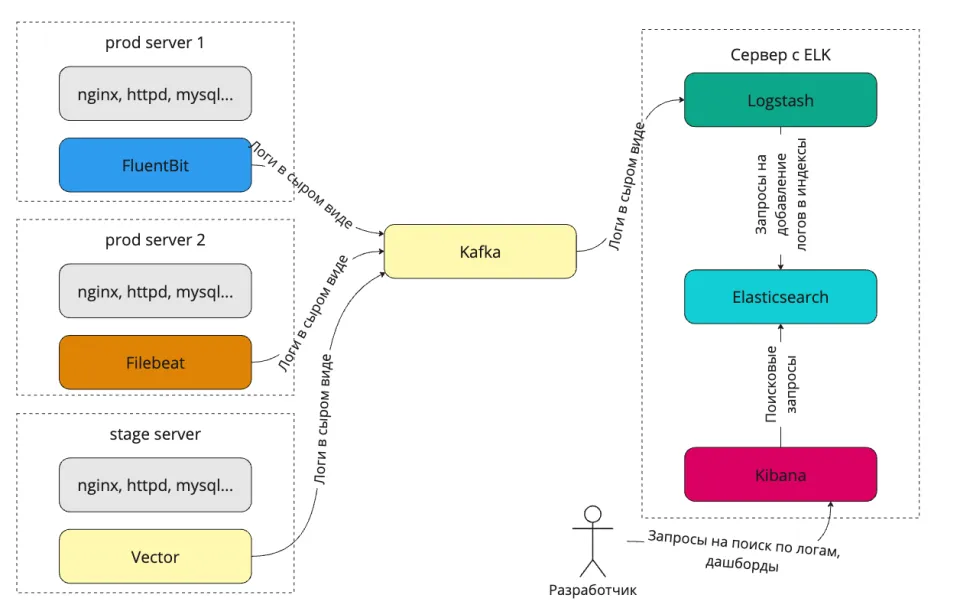
ES прекрасно подходит не только для поиска, но и для сбора/хранения логов. Комбинируя систему с Logstash и Kibana, можно создать мощную систему их обработки. Не обязательно использовать Logstash, вполне достаточно FluentBit, Filebeat, Vector или отправки логов напрямую из приложения через API ES. Если логов очень много, можно перед парсером поставить брокер сообщений.
Ограничения
-
В ES не стоит хранить критически важные данные (заказы, оплаты, заявки и т.д.). Лучше использовать как витрину данных, которых много и из реляционной СУБД они выбираются долго.
-
Нет разграничения по правам на уровне приложения. В Elasticsearch есть пользователи и им можно разграничить права на отдельные индексы и операции в них (создание индексов, добавление записей в индекс, чтение из определенных индексов). Но сделать разграничение прав как в приложении (интернет-магазин, портал и т.д.) силами ES не получится. Ролевая модель на уровне приложения может быть очень сложной и не всегда можно (и нужно) повторить такую же на уровне базы данных (чем и является по сути ES). Можно базово создать что-то своё, но сложные ролевые модели вряд ли получится сделать нормально.
-
Из-за отсутствия «нормальных» связей придется делать промежуточные индексы с денормализованными данными.
-
Нет транзакций как в реляционной СУБД, что может привести к неконсистентным и несогласованным данным в индексах. Если нужно обеспечить выполнение требований ACID — придется реализовывать их на уровне вашего приложения.
Стоимость
ELK представлен в cloud и self-hosted версии и четырьмя типами лицензий. Есть Open Source — бесплатная версия с открытым исходным кодом и Basic — бесплатная версия с некоторыми дополнительными возможностями, но без открытого кода. Для большей части проектов ее достаточно.
Enterprise-лицензии стоят как чугунный мост, несколько тысяч у.е. за ноду. А их нужно минимум три штуки. Плюс проблемы с оплатой из России.
Но решение, как всегда, у нас есть.
Альтернативы
Можно попробовать Open-source платформы:
-
Solr — популярная поисковая система. Как и ES основана на Lucene.
-
OpenSearch — тоже популярная альтернатива. Есть даже managed-решение от ЯндексОблака.
-
ZincSearch — написанный на GO поисковый движок с ES-совместимым API. Позиционируется как более эффективный по потреблению ресурсов.
-
OpenObserve — от авторов ZincSearch, но написан на Rust и только для работы с логами.
Хороший поиск не может быть простым. В него нужно инвестировать, тем более что сегодня существует достаточно платформ под разные бизнес-запросы и бюджеты.
Одни, как Sphinx, подходят для проектов с высокими требованиями к скорости индексации и простоте интеграции, могут обеспечить быстрый поиск при ограниченных ресурсах. Другие, как Elasticsearch, предлагает более мощные функции поиска, гибкость в работе с данными и высокую масштабируемость, что делает их более подходящими для проектов с большими объемами неструктурированных данных.
Если вашему сайту нужно нарастить конверсию, особенно среди посетителей использующих внутренний поиск, стоит задуматься о возможностях его поисковой системы. Вероятно ей требуется модернизация. Мы готовы помочь с выбором и настройкой под ваши особенности, сегменты и тематику. Заполните форму внизу, мы перезвоним и обсудим задачу подробнее.
Статьи по теме




